


Next: EEL6586: HW#5
Up: EEL6586: Homework
Previous: EEL6586: HW#3
Get PDF file
EEL 6586: HW#4
Assignment is due Friday, February 29, 2008 in class. Late
homework loses
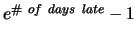 percentage
points. This assignment includes
both matlab and textbook questions.
This assignment must be completed in teams. Only one assignment should be turned in with all the names
of the team members written on the front. The teams have been arbitrarily assigned as follows:
percentage
points. This assignment includes
both matlab and textbook questions.
This assignment must be completed in teams. Only one assignment should be turned in with all the names
of the team members written on the front. The teams have been arbitrarily assigned as follows:
- Arvind Iyer and Yan Yang
- Kiran Kalidindi and Yu Fan
- Salil Bibikar and Steven Spalding
- Avantika Vardhan and Steven Wright
- Karthik Talloju and Jiang Lu
- Surbhi Singhal and Justin Zito
- Padmanabhan Ramakrishnan and Yuelu Liu
- Rahul Chaithanya and Oluwatosin Adeladan
- Reno Varghese and Sarah Keen
- Siddharth Gaddam and Ming Xue
- Keshav Rajan, Duroseme Taylor and Eric Graves
Teammates should work together on each of the problems and agree on their solutions. As in real life, dysfunctional teams will be severely penalized.
PART A: Thought Problems
- A1
- All other factors being equal, do you expect speaker-independent ASR systems to have a lower error rate
than speaker-dependent ASR systems? Explain.
- A2
- Briefly explain how linguistic constraints can improve a speech recognition system.
- A3
- Class
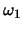 points are:
points are:
Class 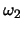 points are:
points are:
Find any weight vector 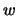 such that
such that 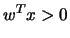 for all class points and
for all class points and  for all class
points. Justify your answer.
for all class
points. Justify your answer.
- A4
- Using the points in [A3] as the training set, classify
![$[1,1,1]^T$](img22.gif) using 3-Nearest Neighbor voting. Remember that in k-NN classification, the k nearest
neighbors of the point are found and the most common class label is used for classification.
using 3-Nearest Neighbor voting. Remember that in k-NN classification, the k nearest
neighbors of the point are found and the most common class label is used for classification.
- A5
- Consider the following sample points:
The samples from class 1
are:
![$ \left[\begin{array}{c} 0 0 \end{array} \right]
\left[\begin{array}{c} 1 1 \end{array} \right]
\left[\begin{array}{c} 2 1 \end{array} \right] $](img23.gif) The samples from class 2 are:
The samples from class 2 are:
![$ \left[ \begin{array}{c} 1 0
\end{array} \right] \left[ \begin{array}{c} 1 ...
... -1 \end{array} \right] \left[
\begin{array}{c} 1 -2 \end{array} \right]$](img24.gif) Sketch the 1-Nearest Neighbor
class boundaries for this set of sample points. Clearly label the class on either side of the
boundary.
Sketch the 1-Nearest Neighbor
class boundaries for this set of sample points. Clearly label the class on either side of the
boundary.
PART B: Phoneme Recognition Experiments
Utterances of 8 vowel phonemes from 38 speakers from the TIMIT
database were extracted (about 2300 utterances total). Your goal
for this problem is to achieve the highest possible recognition accuracy
for this speech corpus. In the end you are free to do whatever
you can to improve recognition accuracy. A demo Matlab program
using 10 linear prediction coefficients and 1-nearest neighbor is provided to demonstrate usage of the
database. The following files are provided:
hw4Data.mat:
Matlab .mat file containing the variables vocab, *Utter, and
*Speaker, where * is one of the phonemes in vocab. *Utter is a
512xN (N varies w/ phoneme) matrix where each column is a 512-pt
utterance extracted from the center (to minimize coarticulation
effects) of a labeled phoneme from the TIMIT database. *Speaker is
an Nx5 character matrix where each row i is the speaker label for
column i in *Utter. *Speaker is provided to ensure that no
speaker appears in both the test/training sets. The size is about 9MB
uncompressed.
hw4Demo.m:
Matlab .m file that demonstrates usage of hw4Data.mat. LPC coeffs
are extracted in bulk, random test/training speakers are designated
for each classifier trial, and the test/training LPC coeffs are used
w/ a 1-Nearest Neighbor classifer. Run this program to make sure
you have downloaded the database properly. Tweak the following
variables to see their effects on accuracy: percentTest,
numTrials, vocab (you can shrink the vocab as a sanity check that
your program works properly-small vocab means high recognition
accuracy). Feel free to modify this code when writing your own
solution.
hw4Readme.txt:
Readme file that describes all files in hw4.zip.
All these files are conveniently available in hw4.zip which can be
found at:
http://www.cnel.ufl.edu/hybrid/courses/EEL6586/hw4.zip
- B1
- Choose a robust feature extraction technique that you
think will provide best results. You may use any feature
extraction techniques you want (energy, zero-crossing, LPC, mfcc,
PLP, hfcc...) or any combination of these. You are free to look at
several different types of feature sets or to invent your own but
do whatever you can to improve the recognition accuracy (without
using test data during training). Explain your choice of feature
set and why you think that it should perform well.
- B2
- Use a classification algorithm to classify the test
data. Again you are free to use any classifier you like (Nearest
Neighbor, Bayes, Neural Network, HMM, ...) Briefly explain why
your choice of a classifier is a wise one (even if you decide to
stay with the nearest neighbor classifier).
- B3
- Always include several trials as in hw4Demo.m and report
the average over all trials. For your final version, make sure to
include at least 100 trials. What is your final accuracy rate?
What is the standard deviation of your accuracy value?
- B4
- For your final optimized system, which two phonemes are
most likely to be confused with one another?
- B5
- Comment on why it is important that no speaker appear in
both the test/training datasets.
As usual, attach all of your code to the end of the assignment. A
total of 5 Bonus points will be awarded to the person(s) with the
highest percentage correct classification.
Next: EEL6586: HW#5
Up: EEL6586: Homework
Previous: EEL6586: HW#3
Dr John Harris
2008-03-19
![\begin{displaymath}
\left[
\begin{array}{c}
-1 \\
-1 \\
+1
\end{array}
...
...[
\begin{array}{c}
+1 \\
-1 \\
-1
\end{array}
\right]
\end{displaymath}](img16.gif)
![\begin{displaymath}
\left[
\begin{array}{c}
+1 \\
+1 \\
-1
\end{array}
...
...[
\begin{array}{c}
-1 \\
+1 \\
+1
\end{array}
\right]
\end{displaymath}](img18.gif)