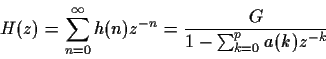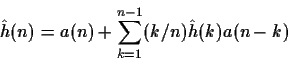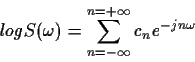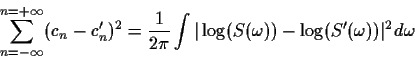Next: About this document ...
Up: EEL6586: Homework Assignments
Previous: EEL6586: HW#3
Due Wednesday, April 18, 2001 in class. Late
homework will lose
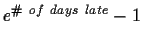 percent.
See
http://www.cnel.ufl.edu/analog/harris/latepoints.html
for penalty.
percent.
See
http://www.cnel.ufl.edu/analog/harris/latepoints.html
for penalty.
PART A: Noncomputer Problems
- A1
- Assuming that
Prove that the complex cepstrum
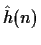 can be derived from the linear
prediction coefficients a(k) using the following relation:
can be derived from the linear
prediction coefficients a(k) using the following relation:
for 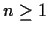 .
.
- A2
- As discussed in class, Euclidean distance in complex cepstral space can be related to a RMS log spectral distance measure. Assuming that
where 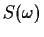 is the power spectrum (magnitude-squared Fourier transform), prove the following:
is the power spectrum (magnitude-squared Fourier transform), prove the following:
where
and
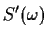 are the power spectra for two different signals.
are the power spectra for two different signals.
- A3
- Describe the advantages and disadvantages of HMM
techniques as compared to DTW techniques for speech recognition.
PART B: Automatic Phoneme Recognition in Matlab
66 utterances of nine different vowel phonemes (iy ih ey eh ae aa ow ax er)
will be used to build a phoneme recognition algorithm (22 speakers, 3 utterances each). 21 utterances of each phoneme will be used to test the classification rate of your classifier (7 speakers, 3 utterances). No speaker is in both the test and training set (Why?). You should download the following files from the course website:
All of the files can be efficiently downloaded in a compressed zip file at
http://www.cnel.ufl.edu/hybrid/courses/EEL6586/hw4.zip
- B1
- Choose a robust feature extraction technique that you think will provide best results. You are free to look at several different types of feature sets or to invent your own but do whatever you can to improve the recognition accuracy (without using test data during training). Explain your choice of feature set.
- B2
- Use a classification algorithm (for example, the nearest neighbor
code in hw4Baseline.m is a good choice) to classify the test data. What is your final accuracy rate? Which two phonemes are most likely to be confused with one another?
As usual, hand in all of your code. 10 Bonus points will be awarded to the person with the best accuracy results.
Next: About this document ...
Up: EEL6586: Homework Assignments
Previous: EEL6586: HW#3
Dr John Harris
2001-04-05