Repeat [C2] above, but instead of using ``clean" TEST utterances, use TEST utterances which have added white Gaussian
noise (AWGN) at a global SNR of 20 dB. ``Global" SNR is defined over an entire utterance, as opposed to ``Local"
SNR, where each frame of speech is set to the same SNR - high-energy frames have more noise added than low-energy
frames (unrealistic since noise level is now speech-dependent which violates the assumption that the noise and
utterance are independent). Report your recognition results on the noisy TEST data and clean TRAIN data as well as
your confusion matrices. Below is code you can use to add AWGN to each utterance:
% Create random sequence of normal distribution (zero mean, unity variance):
noise = randn(size(x)); % x is the "clean" time-domain utterance (whole word)
% Find energy of each utterance and noise:
energyX = sum(x.^2); energyNoise = sum(noise.^2);
% Find amplitude for noise:
noiseAmp = sqrt(energyX/energyNoise*10^(-SNR/10)); % SNR is in dB
% Add noise to utterance:
x = x + noiseAmp*noise;



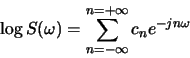
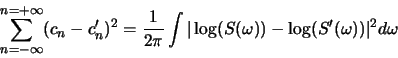
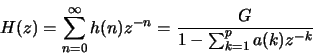
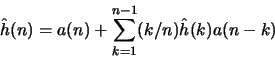
![\begin{displaymath}A_e=A_o=A=\{a_{ij}\}= \left[
\begin{array}{cc}
.9&.1 \\
0&1
\end{array}
\right] \end{displaymath}](img37.gif)
![$B_e=\{b_{i}(k)\}= \left[
\begin{array}{cc}
.8&.7 \\
.1&.1 \\
.1&.2
\end{array}
\right] $](img38.gif)
![$B_o=\{b_{i}(k)\}= \left[
\begin{array}{cc}
.2&.1 \\
.4&.3 \\
.4&.6
\end{array}
\right] $](img39.gif) The columns of the B matrix denote the probabilities of the three symbols (
The columns of the B matrix denote the probabilities of the three symbols (